Пространственная регрессия¶
В предыдущем разделе мы рассматривали пространственную автокорреляцию — то есть проверяли, связаны ли значения показателя в соседних территориальных единицах. С помощью глобального и локального индексов Морана мы могли установить, наблюдается ли в данных пространственная упорядоченность, и где именно она проявляется.
Однако пространственная автокорреляция отвечает лишь на вопрос «есть ли пространственная структура?», но не объясняет, чем она обусловлена.
Во многих практических задачах исследователя интересует не только форма пространственного распределения показателя, но и факторы, которые на него влияют. Например, мы можем хотеть понять, от чего зависит численность населения, плотность услуг или уровень миграции, и как эти зависимости проявляются в пространстве. Для решения подобных задач используется регрессионный анализ.
В самом общем виде регрессия — это инструмент, который позволяет описать, как один показатель (зависимая переменная) связан с другими показателями (объясняющими переменными). Регрессионная модель формализует эту связь и позволяет оценить вклад каждого фактора при прочих равных условиях.
В классической линейной регрессии предполагается, что все наблюдения независимы друг от друга. Однако в пространственных данных это предположение часто нарушается: значения показателя в соседних территориях могут быть связаны между собой, а неучтённые факторы — пространственно сгруппированы. Именно эту зависимость мы выявляли с помощью пространственной автокорреляции.
Если пространственная структура присутствует в данных, но не учитывается в регрессионной модели, это может приводить к искажённым оценкам коэффициентов и ошибочным выводам. В частности, остатки обычной регрессии могут сохранять пространственную автокорреляцию, что указывает на некорректную спецификацию модели.
Пространственная регрессия возникает как естественное продолжение анализа пространственной автокорреляции. Она позволяет включить пространственные связи непосредственно в модель, тем самым учитывая влияние соседних территорий или пространственно структурированных факторов. По сути, пространственная регрессия отвечает на более содержательный вопрос:
как изменяется показатель в пространстве и какие факторы формируют это распределение с учётом соседства?
В этом разделе мы последовательно рассмотрим, как классическая регрессионная модель расширяется для работы с пространственными данными, какие типы пространственных регрессионных моделей используются на практике и как интерпретировать их результаты.
0. Подготовка данных¶
Импортируем библиотеки
import geopandas as gpd
import numpy as np
import osmnx as ox
from pysal.model import spreg
from libpysal.weights import Queen
from pysal.lib import weights
from esda import Moran
from pysal.explore import esdaВ этом разделе мы будем работать с плотностью населения и различных услуг агрегироанных по ячейкам регулярной сетки для Краснодара.
Загружаем данные о плотности населения Краснодара, агрегированные по квадратной сетке регулярных ячеек
sq_grid = gpd.read_file('./data/krs_pop_sqgrid.geojson')
sq_grid.explore(tiles='cartodbpositron')
#Если не отображаются карты, можно воспользоваться обычным plot
# import matplotlib.pyplot as plt
# import contextily as ctx
# fig, ax = plt.subplots(1, 1, figsize=(8, 8))
# sq_grid.plot(
# ax=ax,
# facecolor='none',
# edgecolor='black',
# linewidth=0.3
# )
# ctx.add_basemap(
# ax,
# source=ctx.providers.CartoDB.Positron,
# crs=sq_grid.crs
# )
# ax.set_axis_off()
# plt.show()
Сохраняем СК сетки в переменную и название города, с которым мы работаем
krs_crs = sq_grid.estimate_utm_crs()
place="Krasnodar city"Загружаем точки торговли продуктами из osm
tags_retail = {
'shop': [
'supermarket',
'convenience',
'grocery'
]
}
retail = ox.features_from_place(place, tags_retail)
retail.explore(tiles='cartodbpositron')Фильтруем данные и считаем количество точек по ячейкам регулярной сетки
retail_pts = retail[retail.geometry.type == "Point"].copy()
# убираем пустые геометрии
retail_pts = retail_pts[~retail_pts.geometry.is_empty & retail_pts.geometry.notna()].copy()
# перепроецируем в UTM-зону
retail_pts = retail_pts.to_crs(krs_crs)
# объединяем с ячейками сетки
join = gpd.sjoin(
retail_pts[["geometry"]],
sq_grid[["geometry"]],
how="left",
predicate="within"
)
# считаем количество точек по каждой ячейке
counts = join.groupby("index_right").size().rename("retail_cnt")
# записываем посчитанное в исходную сетку
sq_grid["retail_cnt"] = sq_grid.index.map(counts)
# смотрим на результат
sq_grid.explore(column="retail_cnt", tiles='cartodbpositron',
missing_kwds={
"color": "lightgrey",
"label": "No data"
})
Оставляем только ячейки, находящиеся внутри Краснодара
krs_border = ox.geocode_to_gdf(place)
krs_border_utm = krs_border.to_crs(krs_crs)
krs_grid = sq_grid[sq_grid.intersects(krs_border_utm.geometry.iloc[0])].copy()
krs_grid.explore(column="pop_density", tiles='cartodbpositron')
Отсавляем только ячейки, где есть население (опция 1)
analysis_mask = (
krs_grid['pop_density'].notna() &
(krs_grid['pop_density'] > 0)
)
grid_analysis = krs_grid.loc[analysis_mask].copy()
grid_analysis['retail_cnt'] = (
grid_analysis['retail_cnt']
.fillna(0)
)
grid_analysis.explore(tiles='cartodbpositron')Оставляем только ячейки, где есть население и соседствующие (опция 2)
krs_grid = krs_grid.reset_index(drop=True)
# ячейки с населением
core_mask = (
krs_grid['pop_density'].notna() &
(krs_grid['pop_density'] > 0)
)
# пространственное соседство Queen
w_full = Queen.from_dataframe(krs_grid, ids=krs_grid.index.tolist())
# соседи жилых ячеек
neighbor_idx = set()
for i in krs_grid.index[core_mask]:
neighbor_idx.update(w_full.neighbors[i])
context_mask = krs_grid.index.isin(neighbor_idx)
# итоговая маска: жилые ячейки+ их соседи
analysis_mask = core_mask | context_mask
grid_analysis2 = krs_grid.loc[analysis_mask].copy()
# заменяем на 0 отсуствующие данные
for col in ['retail_cnt', "pop_density"]:
grid_analysis2[col] = grid_analysis2[col].fillna(0)
# смотрим на сетку
grid_analysis2.explore(
tiles='cartodbpositron'
)1. OLS (Ordinary Least Squares)¶
Сначала построим OLS, чтобы получить базовую линейную модель и понять, как плотность населения связана с размещением (или концентрацией) торговых точек. Такая модель служит отправной точкой, с которой потом можно сравнить пространственные модели и увидеть, насколько пространство влияет (и влияет ли) на результаты.
где — значение зависимой переменной в объекте (или пространственной единице) (i); — значение объясняющей переменной; — свободный член; — коэффициент регрессии, отражающий влияние (x) на (y); — случайная ошибка модели.
Подготовка данных для регрессии¶
Логарифмируем показатели — это позволяет сгладить выбросы, приблизить распределение значений к нормальному, что улучшит качество модели
# Готовим переменные для анализа
df = grid_analysis2.copy()
x_name = 'pop_density'
y_name = 'retail_cnt'
# Лог-преобразование (чтобы уменьшить перекос распределений)
df[x_name] = np.log1p(df[x_name])
df[y_name] = np.log1p(df[y_name])
y = df[y_name].values.reshape(-1, 1)# зависимая переменная
X = df[x_name].values.reshape(-1, 1)# объясняющая
Посмотрим на ScatterPlot
Scatterplot позволяет предварительно оценить характер связи между плотностью населения и количеством объектов торговли.
import matplotlib.pyplot as plt
plt.figure(figsize=(6, 6))
plt.scatter(
df[x_name],
df[y_name],
alpha=0.4,
s=15
)
plt.xlabel('ln(population density)')
plt.ylabel('ln(retail count)')
plt.title('Scatterplot: population density vs retail')
plt.grid(True, alpha=0.3)
plt.show()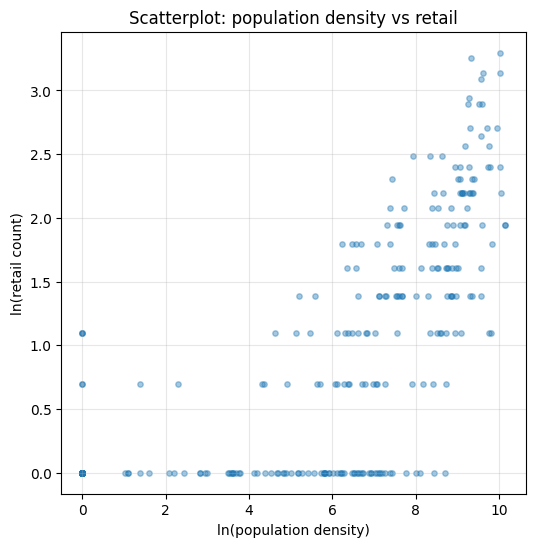
Построим регрессионную модель
ols_model = spreg.OLS(y, X, name_y=y_name, name_x=[x_name])
print(ols_model.summary)REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: ORDINARY LEAST SQUARES
-----------------------------------------
Data set : unknown
Weights matrix : None
Dependent Variable : retail_cnt Number of Observations: 333
Mean dependent var : 0.7800 Number of Variables : 2
S.D. dependent var : 0.9435 Degrees of Freedom : 331
R-squared : 0.5764
Adjusted R-squared : 0.5751
Sum squared residual: 125.212 F-statistic : 450.3457
Sigma-square : 0.378 Prob(F-statistic) : 1.063e-63
S.E. of regression : 0.615 Log likelihood : -309.647
Sigma-square ML : 0.376 Akaike info criterion : 623.295
S.E of regression ML: 0.6132 Schwarz criterion : 630.911
------------------------------------------------------------------------------------
Variable Coefficient Std.Error t-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT -0.13994 0.05491 -2.54851 0.01127
pop_density 0.19046 0.00897 21.22135 0.00000
------------------------------------------------------------------------------------
REGRESSION DIAGNOSTICS
MULTICOLLINEARITY CONDITION NUMBER 2.915
TEST ON NORMALITY OF ERRORS
TEST DF VALUE PROB
Jarque-Bera 2 3.382 0.1843
DIAGNOSTICS FOR HETEROSKEDASTICITY
RANDOM COEFFICIENTS
TEST DF VALUE PROB
Breusch-Pagan test 1 45.516 0.0000
Koenker-Bassett test 1 45.709 0.0000
================================ END OF REPORT =====================================
Интерпретация OLS-модели
Обычная линейная регрессия показывает, что между плотностью населения и количеством торговых точек существует статистически значимая положительная связь. Коэффициент при переменной pop_density = 0.3278 (p < 0.001) указывает на то, что увеличение плотности населения сопровождается ростом количества торговых точек в ячейке. Это означает, что более населённые участки города характеризуются более высокой концентрацией розничной торговли, что соответствует интуитивным ожиданиям и логике спроса.
Качество модели можно оценить как достаточно высокое: значение R² = 0.57 свидетельствует о том, что модель объясняет более половины вариации числа торговых точек. Для пространственно агрегированных городских данных это является хорошим результатом и указывает на важную роль плотности населения в формировании торговой структуры.
Тем не менее, несмотря на относительно высокое значение R², данная модель не учитывает пространственную зависимость, характерную для городских процессов. Это означает, что влияние соседних ячеек и пространственная кластеризация торговли остаются за рамками анализа.
Посмотрим, есть ли какая-то пространственная зависимость у ошибок модели
df['residuals'] = ols_model.u.flatten()
df.explore(
column='residuals',
cmap='RdBu',
legend=True,
tiles='cartodbpositron',
tooltip=['residuals']
)Посчитаем индекс Морана для остатков
w = Queen.from_dataframe(df)
w.transform = 'r'
res = df['residuals'].values
moran_res = Moran(res, w, permutations=999)
print(f"Moran's I: {moran_res.I:.3f}")
print(f"p-value: {moran_res.p_sim:.3f}")Moran's I: 0.154
p-value: 0.001
/var/folders/ry/9bb7wrz54vq_kn2ytlj6ynzm0000gn/T/ipykernel_9064/2224715178.py:1: FutureWarning: `use_index` defaults to False but will default to True in future. Set True/False directly to control this behavior and silence this warning
w = Queen.from_dataframe(df)
После оценки базовой OLS-модели мы видим, что между плотностью населения и плотностью сервисов существует устойчивая статистически значимая связь. Однако в пространственных данных предположение о независимости наблюдений часто нарушается: значения показателя в одной ячейке могут зависеть от значений в соседних ячейках ...
2. SAR — Spatial Autoregressive Model¶
В пространственной авторегрессионной модели (Spatial Autoregressive Model, SAR) предполагается, что значение зависимой переменной в каждой пространственной единице зависит не только от локальных факторов, но и от взвешенного среднего значений зависимой переменной в соседних единицах.
SAR (Spatial Autoregressive Model) — это пространственная регрессионная модель, которая учитывает влияние соседних объектов на значение зависимой переменной. В отличие от обычной линейной регрессии, SAR-модель включает дополнительный компонент — пространственный лаг зависимой переменной (взвешенное среднее значений этой переменной в соседних ячейках).
Где:
— матрица пространственного соседства,
— среднее значение ( Y ) у соседей,
— коэффициент пространственного взаимодействия,
— обычная линейная часть модели.
SAR показывает, как изменения в одной зоне влияют на соседние зоны и наоборот. Такая модель особенно полезна, когда данные образуют пространственные кластеры, и значения ( Y ) зависят от пространственного контекста.
#Готовим переменные для анализа
df = grid_analysis2.copy()
x_name = 'pop_density'
y_name = 'retail_cnt'
# Лог-преобразование (чтобы уменьшить перекос распределений)
df[x_name] = np.log1p(df[x_name])
df[y_name] = np.log1p(df[y_name])
y = df[y_name].values.reshape(-1, 1)# зависимая переменная
X = df[x_name].values.reshape(-1, 1)# объясняющая
w = weights.Queen.from_dataframe(df)
# Посмотрим, есть ли "острова":
print("Number of islands (no neighbors):", len(w.islands))
# Стандартизация весов (row-standardization) — классический вариант для SAR
w.transform = "r"
sar_model = spreg.ML_Lag(
y=y,
x=X,
w=w,
name_y=y_name,
name_x=[x_name]
)
print(sar_model.summary)
Number of islands (no neighbors): 0
REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: MAXIMUM LIKELIHOOD SPATIAL LAG (METHOD = FULL)
-----------------------------------------------------------------
Data set : unknown
Weights matrix : unknown
Dependent Variable : retail_cnt Number of Observations: 333
Mean dependent var : 0.7800 Number of Variables : 3
S.D. dependent var : 0.9435 Degrees of Freedom : 330
Pseudo R-squared : 0.6497
Spatial Pseudo R-squared: 0.6183
Log likelihood : -283.8016
Sigma-square ML : 0.3112 Akaike info criterion : 573.603
S.E of regression : 0.5579 Schwarz criterion : 585.028
------------------------------------------------------------------------------------
Variable Coefficient Std.Error z-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT -0.21977 0.05173 -4.24842 0.00002
pop_density 0.13337 0.01056 12.62858 0.00000
W_retail_cnt 0.44584 0.05716 7.79975 0.00000
------------------------------------------------------------------------------------
SPATIAL LAG MODEL IMPACTS
Impacts computed using the 'simple' method.
Variable Direct Indirect Total
pop_density 0.1334 0.1073 0.2407
================================ END OF REPORT =====================================
/var/folders/ry/9bb7wrz54vq_kn2ytlj6ynzm0000gn/T/ipykernel_9064/3336432674.py:16: FutureWarning: `use_index` defaults to False but will default to True in future. Set True/False directly to control this behavior and silence this warning
w = weights.Queen.from_dataframe(df)
Интерпретация Spatial Lag Model (SAR / ML_Lag)
Пространственная регрессия (SAR) показывает, что размещение розничной торговли определяется не только плотностью населения внутри ячейки, но и уровнем торговли в соседних ячейках. Модель описывает данные существенно лучше, чем обычная линейная регрессия: значение pseudo R² = 0.65 указывает на то, что около двух третей вариации количества торговых точек объясняется с учётом пространственной зависимости.
Коэффициент при переменной pop_density = 0.133 статистически значим (p < 0.001), что подтверждает положительную связь между плотностью населения и количеством торговых точек: более населённые участки города характеризуются более высокой концентрацией розничной торговли. В отличие от обычной линейной регрессии, в пространственной модели этот эффект проявляется не только локально, но и распространяется на соседние территории.
Ключевым элементом модели является коэффициент пространственного лага ρ = 0.446 (p < 0.001), отражающий влияние торговли в соседних ячейках на количество торговых точек в данной ячейке. Его значимость указывает на выраженные агломерационные эффекты: торговые объекты склонны формировать кластеры, усиливая концентрацию друг друга в пространстве
Проанализируем есть ли пространственная зависимость остатков модели
moran_sar_res = esda.Moran(sar_model.u, w)
print(f"SAR residual Moran's I: {moran_sar_res.I:.3f}, p={moran_sar_res.p_sim:.4f}")
df["sar_resid"] = sar_model.u
df.explore(
column="sar_resid",
cmap='RdBu',
legend=True,
tiles='cartodbpositron',
tooltip=["sar_resid"]
)
SAR residual Moran's I: -0.021, p=0.2900
Индекс Морана для остатков SAR-модели не является статистически значимым (Moran’s I = −0.021, p = 0.275), что свидетельствует об отсутствии пространственной автокорреляции в ошибках. Это означает, что пространственная зависимость была адекватно учтена в модели.
SAR-модель выявляет выраженные агломерационные эффекты: торговля склонна формировать пространственные кластеры. Учёт пространственного лага зависимой переменной позволяет устранить автокорреляцию остатков.
3. SLX — Spatial Lag of X Model¶
SLX (Spatial Lag of X Model) — пространственная регрессионная модель, которая учитывает влияние значений факторов у соседних объектов.
В отличие от SAR, SLX не добавляет пространственный лаг зависимой переменной Y. Вместо этого она расширяет обычную линейную регрессию, добавляя пространственные лаги независимых переменных:
Где:
— локальный эффект факторов, как в обычной регрессии
— влияние значений X у соседних объектов
— матрица пространственных весов
— коэффициент пространственного влияния факторов
— случайная ошибка
SLX указывает на то, что влияние факторов распространяется за пределы конкретной территории: Y определяется не только местными условиями, но и характеристиками соседей
# Готовим переменные для анализа
df = grid_analysis2.copy()
x_name = 'pop_density'
y_name = 'retail_cnt'
# Лог-преобразование (чтобы уменьшить перекос распределений)
df[x_name] = np.log1p(df[x_name])
df[y_name] = np.log1p(df[y_name])
y = df[y_name].values.reshape(-1, 1) # зависимая переменная
X = df[[x_name]].values # объясняющая (n x 1)
# Строим пространственные веса
w = weights.Queen.from_dataframe(df)
# Посмотрим, есть ли "острова":
print("Number of islands (no neighbors):", len(w.islands))
# Стандартизация весов (row-standardization)
w.transform = "r"
# Пространственный лаг X: WX
WX = weights.lag_spatial(w, df[x_name].values).reshape(-1, 1)
# SLX: Y = β0 + β1*X + β2*WX + e
X_slx = np.hstack([X, WX])
slx_model = spreg.OLS(
y=y,
x=X_slx,
w=w, # опционально: чтобы в summary были spatial diagnostics
name_y=y_name,
name_x=[x_name, f"W_{x_name}"],
name_w="queen",
name_ds="grid_analysis2"
)
print(slx_model.summary)Number of islands (no neighbors): 0
REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: ORDINARY LEAST SQUARES
-----------------------------------------
Data set :grid_analysis2
Weights matrix : queen
Dependent Variable : retail_cnt Number of Observations: 333
Mean dependent var : 0.7800 Number of Variables : 3
S.D. dependent var : 0.9435 Degrees of Freedom : 330
R-squared : 0.6205
Adjusted R-squared : 0.6182
Sum squared residual: 112.175 F-statistic : 269.7582
Sigma-square : 0.340 Prob(F-statistic) : 3.749e-70
S.E. of regression : 0.583 Log likelihood : -291.342
Sigma-square ML : 0.337 Akaike info criterion : 588.683
S.E of regression ML: 0.5804 Schwarz criterion : 600.108
------------------------------------------------------------------------------------
Variable Coefficient Std.Error t-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT -0.43775 0.07087 -6.17722 0.00000
pop_density 0.12539 0.01352 9.27518 0.00000
W_pop_density 0.12234 0.01976 6.19287 0.00000
------------------------------------------------------------------------------------
REGRESSION DIAGNOSTICS
MULTICOLLINEARITY CONDITION NUMBER 7.139
TEST ON NORMALITY OF ERRORS
TEST DF VALUE PROB
Jarque-Bera 2 1.708 0.4257
DIAGNOSTICS FOR HETEROSKEDASTICITY
RANDOM COEFFICIENTS
TEST DF VALUE PROB
Breusch-Pagan test 2 49.226 0.0000
Koenker-Bassett test 2 43.617 0.0000
================================ END OF REPORT =====================================
/var/folders/ry/9bb7wrz54vq_kn2ytlj6ynzm0000gn/T/ipykernel_9064/2046559664.py:16: FutureWarning: `use_index` defaults to False but will default to True in future. Set True/False directly to control this behavior and silence this warning
w = weights.Queen.from_dataframe(df)
Интерпретация Spatial Lag of X Model (SLX / OLS)
Пространственная регрессия типа SLX (лаг независимых переменных) показывает, что количество торговых точек в ячейке определяется не только плотностью населения внутри неё, но и плотностью населения в соседних ячейках. Модель демонстрирует высокое качество: значение R² = 0.62 указывает на то, что более 60% вариации числа торговых точек объясняется включёнными факторами.
Коэффициент при локальной плотности населения pop_density = 0.125 является статистически значимым (p < 0.001), что подтверждает положительную связь между плотностью населения и количеством торговых точек внутри ячейки. Это означает, что более населённые участки города характеризуются более высокой концентрацией розничной торговли.
Одновременно значимым оказывается и коэффициент при пространственном лаге объясняющей переменной W_pop_density = 0.122 (p < 0.001). Его наличие указывает на то, что плотность населения в соседних ячейках оказывает самостоятельное влияние на количество торговых точек в данной ячейке.
В отличие от пространственной лаговой модели (SAR), SLX-подход не предполагает прямой зависимости значений зависимой переменной между соседними ячейками. Пространственная зависимость в данном случае проявляется через объясняющие факторы, а не через саму торговлю. Это позволяет интерпретировать полученные коэффициенты как эффекты спроса, распространяющиеся на ближайшее окружение.
Посмотрим на пространственное распределение ошибок модели
# Остатки SLX
df['slx_resid'] = slx_model.u
# Moran's I для остатков
moran_slx = esda.Moran(df['slx_resid'], w)
print(
f"SLX residual Moran's I: "
f"{moran_slx.I:.3f}, p={moran_slx.p_sim:.4f}"
)
# Карта остатков
df.explore(
column='slx_resid',
cmap='RdBu',
legend=True,
tiles='cartodbpositron',
tooltip=['slx_resid']
)
SLX residual Moran's I: 0.145, p=0.0010
SLX-модель показывает, что размещение торговли зависит не только от локальной плотности населения, но и от плотности торговых в соседних ячейках. Однако пространственная зависимость в самой торговле при этом остаётся неучтённой.
4. SEM — Spatial Error Model¶
SEM (Spatial Error Model) — это пространственная регрессионная модель, которая учитывает, что ошибки модели могут быть пространственно зависимыми. Такой подход применяется в тех случаях, когда пространственная структура возникает не в самой зависимой переменной Y, а в пропущенных или неучтённых факторах, значения которых сходны у соседних территорий.
В отличие от SAR, SEM не добавляет пространственный лаг Y. Вместо этого она моделирует пространственную зависимость в ошибках:
Где:
— обычная линейная часть модели, как в OLS
— ошибка модели
— матрица пространственных весов
— коэффициент пространственной автокорреляции ошибок
— обычная случайная ошибка (i.i.d.)
SEM показывает, что сходство между соседними зонами возникает не из-за того, что они влияют друг на друга напрямую, а потому что у них общие скрытые условия, которые модель не учитывает.
# Готовим переменные для анализа
df = grid_analysis2.copy()
x_name = 'pop_density'
y_name = 'retail_cnt'
# Лог-преобразование (чтобы уменьшить перекос распределений)
df[x_name] = np.log1p(df[x_name])
df[y_name] = np.log1p(df[y_name])
y = df[y_name].values.reshape(-1, 1) # зависимая переменная
X = df[x_name].values.reshape(-1, 1) # объясняющая
# Пространственные веса
w = weights.Queen.from_dataframe(df)
# Посмотрим, есть ли "острова":
print("Number of islands (no neighbors):", len(w.islands))
# Стандартизация весов (row-standardization) — классический вариант для SEM
w.transform = "r"
# SEM (Spatial Error Model): пространственная зависимость в ошибках
sem_model = spreg.ML_Error(
y=y,
x=X,
w=w,
name_y=y_name,
name_x=[x_name]
)
print(sem_model.summary)
Number of islands (no neighbors): 0
/var/folders/ry/9bb7wrz54vq_kn2ytlj6ynzm0000gn/T/ipykernel_9064/2055294796.py:16: FutureWarning: `use_index` defaults to False but will default to True in future. Set True/False directly to control this behavior and silence this warning
w = weights.Queen.from_dataframe(df)
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/spreg/ml_error.py:184: RuntimeWarning: Method 'bounded' does not support relative tolerance in x; defaulting to absolute tolerance.
res = minimize_scalar(
REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: ML SPATIAL ERROR (METHOD = full)
---------------------------------------------------
Data set : unknown
Weights matrix : unknown
Dependent Variable : retail_cnt Number of Observations: 333
Mean dependent var : 0.7800 Number of Variables : 2
S.D. dependent var : 0.9435 Degrees of Freedom : 331
Pseudo R-squared : 0.5764
Log likelihood : -296.0566
Sigma-square ML : 0.3328 Akaike info criterion : 596.113
S.E of regression : 0.5768 Schwarz criterion : 603.730
------------------------------------------------------------------------------------
Variable Coefficient Std.Error z-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT 0.02527 0.07957 0.31757 0.75081
pop_density 0.15815 0.01091 14.49823 0.00000
lambda 0.48304 0.07215 6.69492 0.00000
------------------------------------------------------------------------------------
================================ END OF REPORT =====================================
Интерпретация Spatial Error Model (SEM / ML_Error)
Пространственная модель ошибок (SEM) показывает, что связь между плотностью населения и количеством торговых точек остаётся статистически значимой даже после учёта пространственной зависимости в ненаблюдаемых факторах. Значение pseudo R² = 0.58 указывает на то, что модель объясняет более половины вариации числа торговых точек, что сопоставимо с результатами других пространственных моделей.
Коэффициент при переменной pop_density = 0.158 является положительным и статистически значимым (p < 0.001), что подтверждает устойчивую связь между плотностью населения и размещением розничной торговли: более населённые участки города характеризуются большей концентрацией торговых объектов. По сравнению с OLS и SLX, величина этого коэффициента несколько выше, что может указывать на смещение оценок в моделях, не учитывающих пространственную корреляцию ошибок.
Ключевым элементом SEM является коэффициент пространственной зависимости в ошибках λ = 0.483 (p < 0.001). Его статистическая значимость указывает на наличие пространственно коррелированных ненаблюдаемых факторов, влияющих на размещение торговли. К таким факторам могут относиться особенности городской структуры, транспортная доступность, зонирование или исторически сложившиеся центры активности, которые не были напрямую включены в модель.
В отличие от SAR-модели, где пространственная зависимость интерпретируется как прямое влияние соседних значений зависимой переменной, SEM предполагает, что пространственная структура проявляется через ошибки модели, а не через саму торговлю.
SEM-модель указывает на влияние пространственно коррелированных неучтённых факторов. В данном случае пространственная структура проявляется не в самой торговле, а в ошибках модели.
5. Сравнение пространственных моделей (SAR, SLX, SEM)¶
| Критерий | SAR (ML_Lag) | SLX (OLS + WX) | SEM (Spatial Error) |
|---|---|---|---|
| Как учитывается пространственный фактор | Пространственный лаг зависимой переменной Y (среднее значение торговли у соседних ячеек) | Пространственный лаг объясняющей переменной X (средняя плотность населения у соседей) | Пространственная корреляция ошибок модели |
| Что моделирует | Агломерацию торговли: влияние количества торговых точек у соседей | Пространственный спрос: влияние населения в соседних ячейках | Влияние неучтённых пространственных факторов |
| Зависимая переменная (Y) | Количество торговых точек (retail_cnt) | Количество торговых точек (retail_cnt) | Количество торговых точек (retail_cnt) |
| Ключевой пространственный параметр | ρ = 0.446 (p < 0.001) | θ = 0.122 (W_pop_density, p < 0.001) | λ = 0.483 (p < 0.001) |
| Эффект плотности населения | Прямой + косвенный (total effect = 0.241) | Локальный (0.125) + соседский (0.122) | Локальный (0.158) |
| Качество модели | Pseudo R² = 0.65 | R² = 0.62 | Pseudo R² = 0.58 |
| Log-likelihood | –283.80 | –291.34 | –296.06 |
| AIC | 573.60 | 588.68 | 596.11 |
| Остаточная пространственная автокорреляция | Отсутствует (Moran’s I ≈ 0, p > 0.05) | Возможна (проверяется отдельно) | Как правило устранена |
| Интерпретация пространственного эффекта | «Торговля тянется к торговле: кластеры усиливают друг друга» | «Торговля реагирует не только на локальный спрос, но и на спрос вокруг» | «Соседние районы имеют схожие скрытые условия размещения торговли» |
Сравнение моделей показывает, что SAR-модель лучше всего описывает пространственную структуру размещения торговли, что указывает на наличие агломерационных эффектов. SLX-модель подчёркивает важность пространственно распределённого спроса, тогда как SEM фиксирует влияние ненаблюдаемых факторов городской среды.
6. Итог¶
Рассмотренные модели пространственной регрессии показывают, что пространственная зависимость может проявляться по-разному: через агломерацию значений зависимой переменной, через пространственно распределённые факторы спроса или через неучтённые условия среды.
SLX, SAR и SEM-модели решают разные аналитические задачи и не являются взаимозаменяемыми.
Выбор конкретной модели должен опираться не только на статистические критерии, но и на исследовательскую гипотезу и интерпретацию пространственных процессов.