1. Кластеризация¶
Кластеризация — один из основных методов анализа многомерных данных. Её цель заключается в том, чтобы сгруппировать наблюдения таким образом, чтобы объекты внутри одной группы были более похожи друг на друга, чем на объекты из других групп. Полученные группы называют кластерами, а сам процесс их выделения — кластеризацией.
Результаты кластеризации позволяют упростить интерпретацию сложных данных. Каждый кластер можно охарактеризовать с помощью обобщённого профиля, отражающего типичные значения исходных переменных. Благодаря этому можно анализировать не отдельные наблюдения, а ограниченное число кластеров.
В этом разделе мы посмотрим на несколько методов кластеризации на основе демографических данных Приволжского Федерального округа
0. Подготовка данных¶
Импортируем библиотеки
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
import numpy
*Загружаем данные о муниципалитетах для Приволжского федерального округа
muni = gpd.read_file('./data/muni_pfo.geojson')
muni.explore(tiles='cartodbpositron')Мы будем работать с тремя показателями:
коэффициент рождаемости (dem_birth_rate),
коэффициент смертности (dem_mortality_rate),
коэффициент сальдо миграции (dem_migration_rate).
В настоящее время значения представлены в долях. Для удобства интерпретации создадим новые переменные, в которых переведём эти показатели в промилле — то есть в расчёте на 1000 человек населения.
# Список столбцов, которые нужно перевести в промилле
cols = ['dem_birth_rate', 'dem_mortality_rate', 'dem_migration_rate']
# Создаем новые столбцы с суффиксом _permille
for col in cols:
muni[col + '_permille'] = muni[col] * 1000
Визуализируем значения этих показателей на карте, чтобы посмотреть есть ли некоторые пространственные закономерности.
import matplotlib.pyplot as plt
import matplotlib.colors as colors
# Показатели (в промилле)
cols_analysis = [
'dem_birth_rate_permille', # рождаемость: последовательная шкала
'dem_mortality_rate_permille', # смертность: последовательная шкала
'dem_migration_rate_permille' # миграция: дивергентная шкала через 0
]
# Создаем фигуру с 3 картами в один ряд
f, axs = plt.subplots(nrows=1, ncols=3, figsize=(12, 12))
axs = axs.flatten()
# --- 1) и 2) Последовательные шкалы ---
for i, col in enumerate(cols_analysis[:2]):
ax = axs[i]
muni.plot(
column=col,
ax=ax,
scheme="NaturalBreaks", # разбиение на квантильные классы
k=5, # число классов
linewidth=0,
cmap="RdPu", # последовательная палитра
legend=True,
legend_kwds={
"fontsize": 8, # размер шрифта
"title_fontsize": 9 # размер заголовка легенды
}
)
# Убираем оси/рамки
ax.set_axis_off()
# Заголовок карты
ax.set_title(col)
# --- 3) Расходящаяся шкала через 0 для миграции ---
col = cols_analysis[2]
ax = axs[2]
# Делаем диапазон симметричным относительно 0: [-M, 0, +M]
vmin = float(muni[col].min())
vmax = float(muni[col].max())
M = max(abs(vmin), abs(vmax))
norm = colors.TwoSlopeNorm(vmin=-M, vcenter=0, vmax=M)
muni.plot(
column=col,
ax=ax,
linewidth=0,
cmap="RdBu_r",
norm=norm,
legend=True,
legend_kwds={
"shrink": 0.2, # уменьшить размер colorbar
"aspect": 20, # сделать более компактным
"label": "Миграция (‰)"
}
)
ax.set_axis_off()
ax.set_title(col)
plt.show()
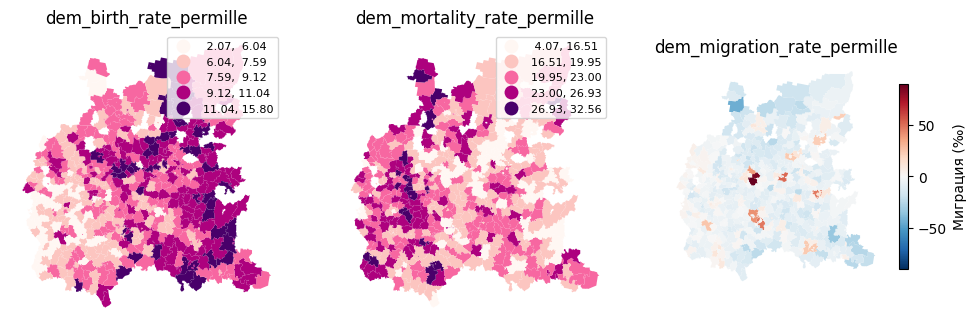
На картах сразу можно увидеть некоторые пространственные закономерности.
Во-первых, значения коэффициента рождаемости, ‰ (dem_birth_rate_permille), на востоке в среднем выше, чем на западе. Для коэффициента смертности, ‰ (dem_mortality_rate_permille), прослеживается противоположная тенденция.
По показателю миграционного прироста, ‰ (dem_migration_rate_permille), выделяются отдельные локальные центры, что может свидетельствовать о наличии «точек притяжения».
Наблюдаемые пространственные различия позволяют предположить, что территории могут быть сгруппированы по сходству демографического профиля. Чтобы формально выявить такие группы, перейдём к методам кластерного анализа.
1.1 K-Means¶
K-means — один из наиболее распространённых методов кластеризации. Его цель — разделить набор наблюдений на заранее заданное число групп (кластеров) так, чтобы объекты внутри одной группы были максимально похожи друг на друга и максимально отличались от объектов других групп.
Алгоритм минимизирует внутрикластерное расстояние: каждое наблюдение должно находиться как можно ближе к «центру» своего кластера. В качестве центра используется многомерное среднее значение признаков — центроид.
Как работает алгоритм
Процедура состоит из повторяющихся шагов:
Инициализация. Задаётся число кластеров ( k ). Наблюдения случайным образом распределяются по кластерам (или случайно выбираются начальные центроиды).
Шаг присвоения. Каждое наблюдение относится к тому кластеру, чей центроид находится к нему ближе всего (обычно по евклидову расстоянию).
Шаг обновления. Для каждого кластера пересчитывается новый центроид как среднее значение всех объектов, вошедших в этот кластер.
Шаги 2 и 3 повторяются до тех пор, пока распределение объектов по кластерам перестаёт изменяться.
Алгоритм требует заранее задать число кластеров ( k ). На практике оптимальное значение ( k ) обычно неизвестно и определяется дополнительно
В примере далее будет использовано значение ( k = 5 ) при применении алгоритма KMeans из библиотеки scikit-learn.
1.1.1 Подготовка данных¶
Алгоритм K-means не работает с пропущенными значениями (NaN), поэтому нужно либо удалить наблюдения с пропусками, либо заполнить пропуски (импутация). В демонстрационном примере сначала удалим строки, где хотя бы один из признаков отсутствует.
muni_clean = muni.dropna(subset=cols_analysis).copy()Поскольку алгоритм K-means основан на расстояниях между наблюдениями, переменные были предварительно стандартизированы. Это позволяет избежать доминирования показателей с большей вариацией и обеспечивает сопоставимый вклад всех признаков в формирование кластеров.
from sklearn.preprocessing import robust_scale
# Масштабирование признаков перед кластеризацией
# Используется robust_scale, который центрирует данные по медиане
# и масштабирует их с использованием межквартильного размаха (IQR).
# Такой подход менее чувствителен к выбросам по сравнению
# со стандартной z-стандартизацией.
muni_scaled = robust_scale(muni_clean[cols_analysis])1.1.2 Расчёт кластеров¶
После предварительного масштабирования переменных можно переходить к кластеризации.
В данном примере используется алгоритм KMeans из библиотеки scikit-learn с числом кластеров ( k = 5 ).
Значение выбрано в демонстрационных целях.
Для обеспечения воспроизводимости результатов фиксируется значение генератора случайных чисел.
# Импорт алгоритма KMeans
from sklearn.cluster import KMeans
# Инициализация модели KMeans
# n_clusters=5 означает, что данные будут разделены на 5 кластеров
kmeans = KMeans(n_clusters=5)
# Фиксируем генератор случайных чисел для воспроизводимости (чтобы получать одинаковые результаты при каждом запуске)
numpy.random.seed(1234)
# Запуск алгоритма K-means на масштабированных данных
# Метод fit выполняет итеративную процедуру кластеризации
k5cls = kmeans.fit(muni_scaled)
# Вывод первых пяти меток кластеров
# Каждое число соответствует номеру кластера,
# к которому было отнесено наблюдение
k5cls.labels_[:5]
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
array([4, 4, 4, 4, 4], dtype=int32)Числовые значения меток -- обозначения принадлежности кластерам. Давайте посмотрим на то, как кластеры распределяются в пространстве.
1.1.3 Пространственное распределение кластеров¶
Визуализируем полученные кластеры на карте, чтобы оценить, проявляются ли пространственные закономерности в их размещении и формируют ли они территориально выраженные группы.
# Записываем номера кластеров в таблицу
muni_clean["k5cls"] = k5cls.labels_
# Создаём фигуру и ось
f, ax = plt.subplots(1, figsize=(9, 9))
# Строим картограмму кластеров с легендой
muni_clean.plot(
column="k5cls",
categorical=True,
legend=True,
linewidth=0,
ax=ax
)
# Убираем оси координат
ax.set_axis_off()
# Отображаем карту
plt.show()
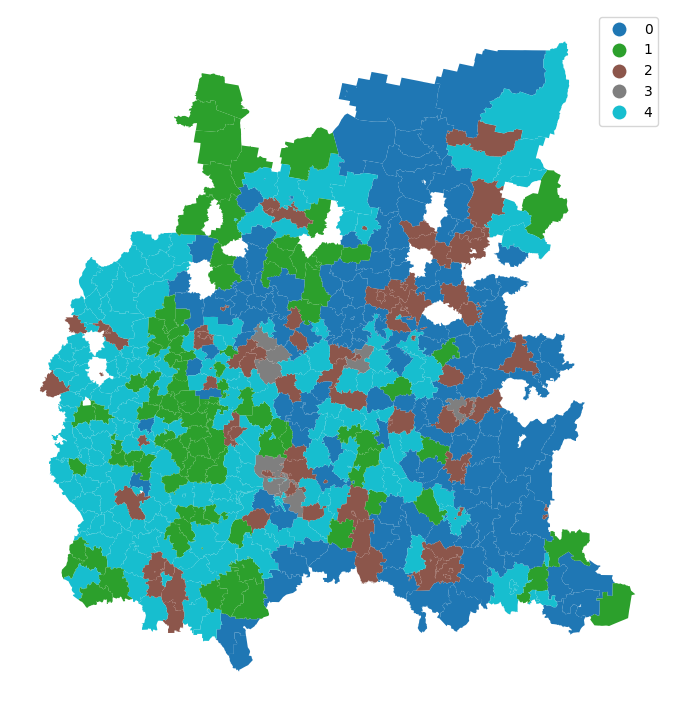
Полученная карта выглядит достаточно интересной и одновременно требует дополнительной интерпретации. Однако уже при первом взгляде на результат хочется вспомнить первый закон географии Тоблера, согласно которому пространственно близко расположенные территориальные единицы, как правило, более похожи друг на друга, чем те, которые находятся на значительном расстоянии. И действительно, на карте мы видим, что соседние муниципалитеты часто относятся к одному и тому же кластеру, формируя пространственно компактные группы.
1.1.4 Статистический анализ кластеров¶
В дополнение к пространственной визуализации целесообразно рассмотреть профили кластеров, то есть проанализировать их характеристики.
В качестве первого шага можно оценить кардинальность кластеров — количество наблюдений, относящихся к каждому кластеру. Это позволяет понять, насколько сбалансировано распределение объектов между группами и не формируются ли чрезмерно малочисленные или, наоборот, доминирующие кластеры.
Далее можно перейти к анализу средних значений исходных показателей внутри каждого кластера, что позволит интерпретировать их с точки зрения демографического профиля.
Количество объектов по кластерам
# Группируем данные по номеру кластера и считаем количество наблюдений в каждом
k5sizes = muni_clean.groupby("k5cls").size()
k5sizesk5cls
0 139
1 92
2 76
3 7
4 186
dtype: int64Между размерами пяти кластеров наблюдаются значительные различия: два кластера являются очень крупными (0 и 4), два имеют средние размеры (1 и 2), и один словсем маленький (3). Мы это также можем увидеть и на карте выше.
Профиль кластеров
Построим boxplot-диаграммы по каждому показателю в разрезе кластеров. Такой способ визуализации позволяет оценить не только средний уровень признака, но и его вариацию, медиану и возможные выбросы внутри каждой группы.
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
for i, col in enumerate(cols_analysis):
muni_clean.boxplot(
column=col,
by="k5cls",
ax=axes[i]
)
axes[i].set_title(f"{col}")
axes[i].set_xlabel("Кластер")
axes[i].set_ylabel("Значение (‰)")
plt.suptitle("Распределение показателей по кластерам")
plt.tight_layout()
plt.show()
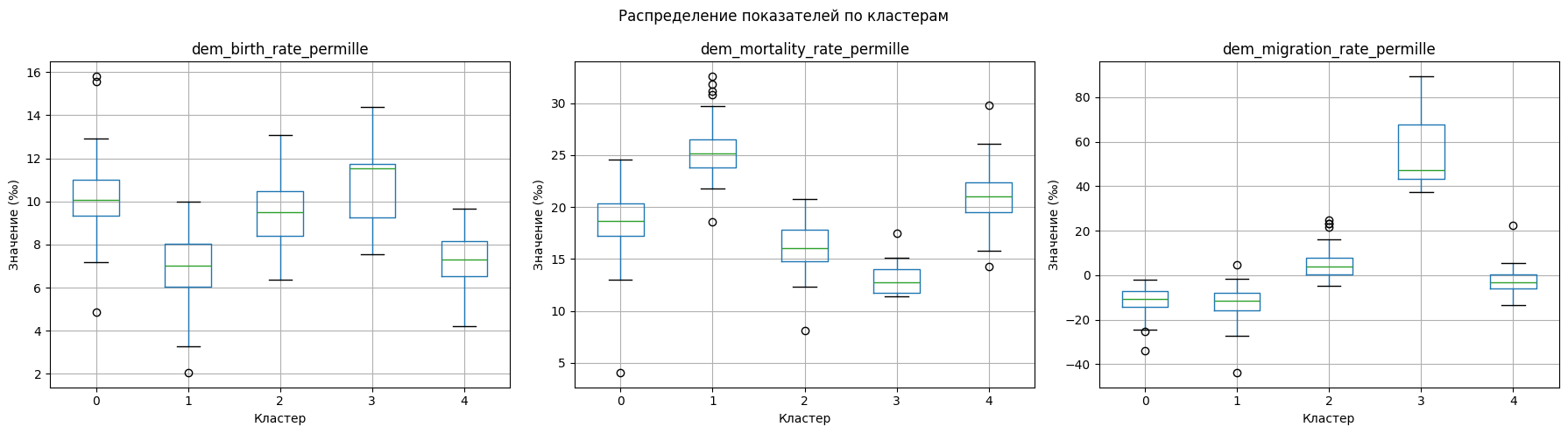
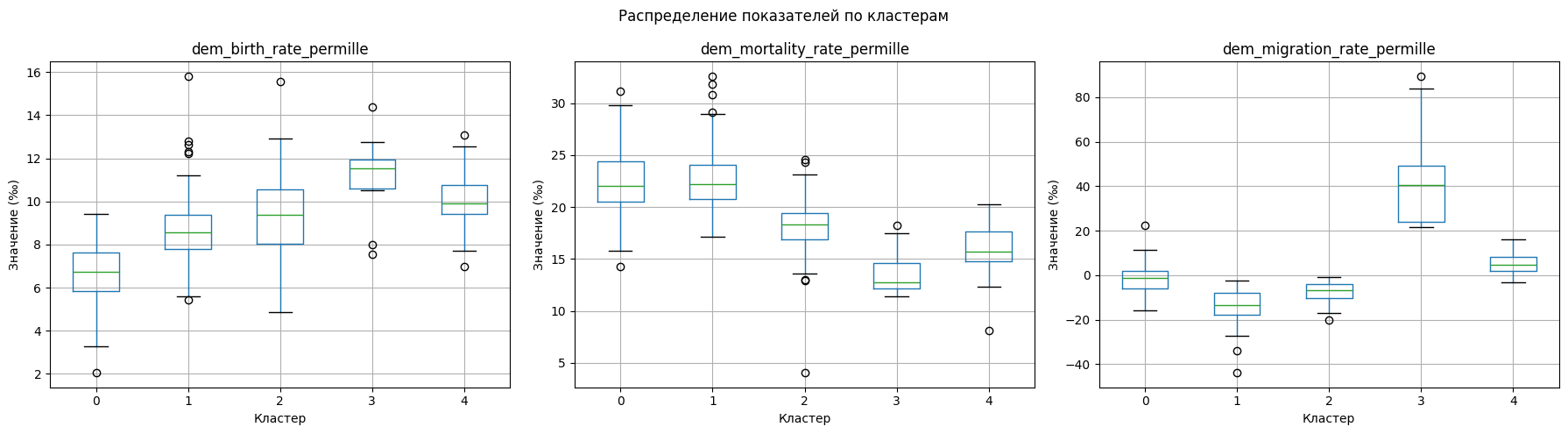
Благодаря такой визуализации мы можем увидеть принипицальные отличия между кластерами.
Кластер 1 характеризуется наиболее высокими значениями смертности при относительно низкой рождаемости и отрицательном миграционном приросте.
Кластер 3, напротив, выделяется наиболее высоким положительным миграционным приростом при умеренных уровнях рождаемости и относительно низкой смертности. Вероятно, сюда входят территории с выраженной миграционной привлекательностью.
Кластер 2 демонстрирует умеренные значения по всем показателям: средний уровень рождаемости и смертности и слабоположительный миграционный баланс.
Кластеры 0 и 4 занимают промежуточное положение, однако различаются по структуре: например, кластер 4 характеризуется более высокой смертностью при умеренно отрицательной миграции, тогда как кластер 0 показывает умеренную смертность и выраженный отрицательный миграционный баланс.
1.2 Hierarchical Clustering¶
K-means — лишь один из методов кластерного анализа. На практике существует множество альтернативных подходов. В этом разделе рассмотрим ещё один базовый метод — агломеративную иерархическую кластеризацию (Agglomerative Hierarchical Clustering, AHC).
В отличие от K-means, данный алгоритм не сразу формирует фиксированное число кластеров, а строит иерархию объединений.
Процесс начинается с ситуации, когда каждое наблюдение рассматривается как отдельный кластер. Далее кластеры постепенно объединяются между собой, пока в итоге все наблюдения не окажутся в одном общем кластере.
Алгоритм работает следующим образом:
Каждое наблюдение образует собственный кластер.
Выбираются два наиболее близких кластера
Эти кластеры объединяются в один.
Процедура повторяется до тех пор, пока все наблюдения не окажутся объединены.
Хотя алгоритм строит полную иерархию объединений, для практического использования всё равно необходимо выбрать, на каком уровне эту иерархию «разрезать», то есть задать итоговое число кластеров.
1.2.1 Подготовка данных¶
Этап подготовки данных в данном разделе отдельно рассматриваться не будет, поскольку он уже был выполнен ранее при реализации метода k-средних.
Для дальнейшего анализа будем использовать ранее подготовленные переменные muni_clean и muni_scaled
1.2.2 Расчёт кластеров¶
В данном примере используется алгоритм Agglomerative Clustering (иерархическая агломеративная кластеризация) из библиотеки scikit-learn с числом кластеров (k = 5).
Число кластеров выбрано в демонстрационных целях.
Метод ward минимизирует внутрикластерную дисперсию и по логике близок к подходу k-means, однако формирует кластеры последовательно, объединяя наиболее близкие группы наблюдений.
from sklearn.cluster import AgglomerativeClustering
# Фиксируем генератор случайных чисел для воспроизводимости (чтобы получать одинаковые результаты при каждом запуске)
numpy.random.seed(0)
# Инициализация модели агломеративной кластеризации
# linkage="ward" — метод объединения кластеров (минимизация внутрикластерной дисперсии)
# n_clusters=5 — задаём число кластеров
model = AgglomerativeClustering(linkage="ward", n_clusters=5)
# Обучение модели на стандартизированных данных
model.fit(muni_scaled)
# Сохраняем номера кластеров в исходную таблицу
muni_clean["ward5"] = model.labels_1.2.3 Пространственное распределение кластеров¶
Визуализируем полученные кластеры на карте, чтобы оценить, проявляются ли пространственные закономерности в их размещении и формируют ли они территориально выраженные группы.
# Создаём фигуру и ось
f, ax = plt.subplots(1, figsize=(9, 9))
# Строим картограмму кластеров с легендой
muni_clean.plot(
column="ward5",
categorical=True,
legend=True,
linewidth=0,
ax=ax
)
# Убираем оси координат
ax.set_axis_off()
# Отображаем карту
plt.show()
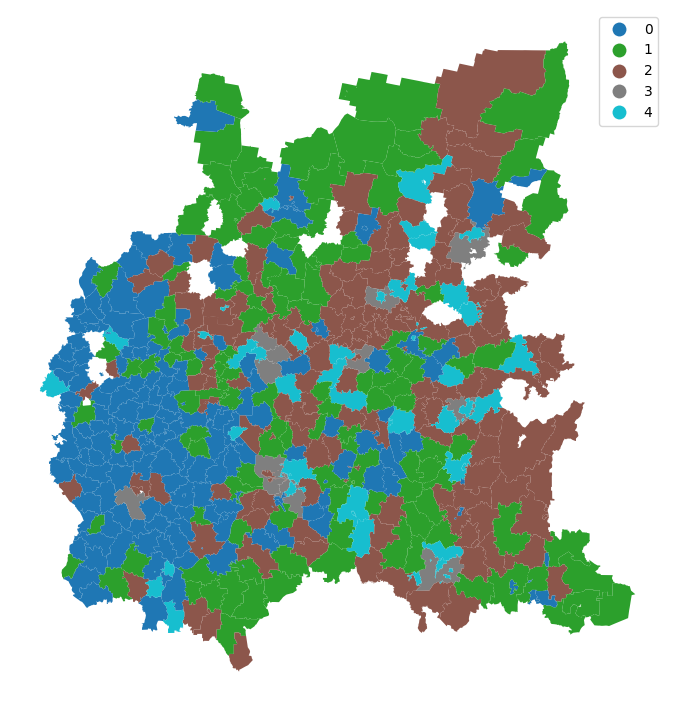
1.2.4 Статистический анализ кластеров¶
Как и в предыдущем методе рассмотрим профили кластеров.
Количество объектов по кластерам
# Группируем данные по номеру кластера и считаем количество наблюдений в каждом
ward5sizes = muni_clean.groupby("ward5").size()
ward5sizesward5
0 165
1 127
2 153
3 11
4 44
dtype: int64Профиль кластеров
Построим boxplot-диаграммы по каждому показателю в разрезе кластеров. Такой способ визуализации позволяет оценить не только средний уровень признака, но и его вариацию, медиану и возможные выбросы внутри каждой группы.
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
for i, col in enumerate(cols_analysis):
muni_clean.boxplot(
column=col,
by="ward5",
ax=axes[i]
)
axes[i].set_title(f"{col}")
axes[i].set_xlabel("Кластер")
axes[i].set_ylabel("Значение (‰)")
plt.suptitle("Распределение показателей по кластерам")
plt.tight_layout()
plt.show()
1.3. Сравнение двух подходов кластеризации¶
Для сопоставления результатов метода k-средних и иерархической кластеризации воспользуемся таблицей сопряжённости и численной мерой сходства разбиений.
Сначала построим таблицу перекрёстного распределения наблюдений по кластерам:
pd.crosstab(muni_clean["k5cls"], muni_clean["ward5"])
Таблица показывает, как объекты, отнесённые к определённому кластеру методом k-means, распределяются по кластерам, полученным методом Ward.
В нашем случае видно, что некоторые группы имеют заметные пересечения, однако классы всё же отличаются.
Для количественной оценки степени согласованности кластеризаций используем Adjusted Rand Index (ARI) — скорректированный индекс Рэнда:
from sklearn.metrics import adjusted_rand_score
ari = adjusted_rand_score(muni_clean["k5cls"], muni_clean["ward5"])
ari
0.25727501752373966Индекс ARI принимает значения:
1 — полное совпадение разбиений,
0 — совпадение на уровне случайности,
значения меньше 0 — хуже случайного совпадения.
Полученное значение ARI показывает, что методы демонстрируют лишь частичное согласие. Это ожидаемый результат, поскольку k-means и иерархическая кластеризация используют разные алгоритмические принципы формирования групп.
Таким образом, несмотря на использование одинакового числа кластеров (( k = 5 )), различные методы кластеризации могут приводить к различным структурам группировки данных. Это подчёркивает важность проверки устойчивости результатов и сравнения нескольких алгоритмов при проведении кластерного анализа.
Несмотря на выявленные различия между методами, оба подхода формируют кластеры без учёта пространственной связности территорий. В результате отдельные группы могут быть фрагментированы и состоять из пространственно разрозненных участков.
Чтобы учесть фактор пространственной смежности и обеспечить формирование территориально целостных групп, далее рассмотрим методы регионализации.
2. Регионализация¶
2.1 Пространственное ограничение связности (contiguity constraint)¶
В предыдущем разделе мы получили кластеры, которые объединяют территории по сходству показателей. Однако такие кластеры могут быть пространственно разорванными: территории одного кластера могут находиться в разных частях карты и не иметь общих границ.
В ряде прикладных задач этого недостаточно. Например, при формировании районов или аналитических зон важно, чтобы каждая группа представляла собой цельную, непрерывную территорию.
Именно эту задачу решает регионализация. В отличие от обычной кластеризации, здесь к условию статистического сходства добавляется пространственное ограничение: территории могут объединяться в одну группу только если они граничат друг с другом.
Таким образом, регионы — это группы, которые одновременно:
однородны по своим характеристикам,
и пространственно связаны.
Как и в кластеризации, существует несколько методов регионализации. Все они используют два типа информации:
значения показателей (атрибуты);
информацию о соседстве территорий (матрицу пространственных весов).
В дальнейшем мы рассмотрим агломеративную иерархическую кластеризацию с добавленным пространственным ограничением. В библиотеке scikit-learn это реализуется через параметр connectivity, который позволяет объединять в один кластер только соседние территории.
2.1.1 Подготовка данных¶
В данном разделе мы также будем использовать ранее подготовленные переменные muni_clean и muni_scaled.
Однако в отличие от стандартной кластеризации, методы регионализации требуют учёта пространственной связности территорий. Для этого необходимо задать структуру соседства — определить, какие муниципальные образования считаются смежными.
Воспользуемся критерий Queen contiguity, при котором территории считаются соседними, если имеют общую границу или хотя бы одну общую точку.
from libpysal.weights import Queen
w = Queen.from_dataframe(muni_clean)/var/folders/ry/9bb7wrz54vq_kn2ytlj6ynzm0000gn/T/ipykernel_8400/1034096385.py:2: FutureWarning: `use_index` defaults to False but will default to True in future. Set True/False directly to control this behavior and silence this warning
w = Queen.from_dataframe(muni_clean)
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/libpysal/weights/contiguity.py:347: UserWarning: The weights matrix is not fully connected:
There are 2 disconnected components.
There is 1 island with id: 39.
W.__init__(self, neighbors, ids=ids, **kw)
2.1.2 Создание регионов¶
В данном примере используется алгоритм регионализации, основанный на агломеративном объединении территорий, с заданным числом регионов ( k = 5 ).
Число регионов, как и ранее, выбрано в демонстрационных целях для сопоставимости результатов с методами кластеризации.
В отличие от стандартной агломеративной кластеризации, при регионализации дополнительно учитывается пространственная связность. Это означает, что объединяться могут только соседние территории, заданные через матрицу пространственных весов.
Таким образом, алгоритм минимизирует внутригрупповую неоднородность (по аналогии с методом Ward), но при этом формирует пространственно непрерывные регионы, исключая фрагментацию.
Если ранее мы получали статистически однородные кластеры, то теперь формируем статистически однородные и одновременно территориально целостные регионы.
# Фиксируем генератор случайных чисел для воспроизводимости (чтобы получать одинаковые результаты при каждом запуске)
numpy.random.seed(123456)
# Инициализируем модель агломеративной кластеризации
# linkage="ward" — минимизация внутригрупповой дисперсии
# connectivity=w.sparse — учёт пространственной связности
# n_clusters=5 — число формируемых регионов
model = AgglomerativeClustering(
linkage="ward",
connectivity=w.sparse,
n_clusters=5
)
# Обучаем модель на стандартизированных данных
model.fit(muni_scaled)
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/sklearn/cluster/_agglomerative.py:282: UserWarning: the number of connected components of the connectivity matrix is 2 > 1. Completing it to avoid stopping the tree early.
connectivity, n_connected_components = _fix_connectivity(
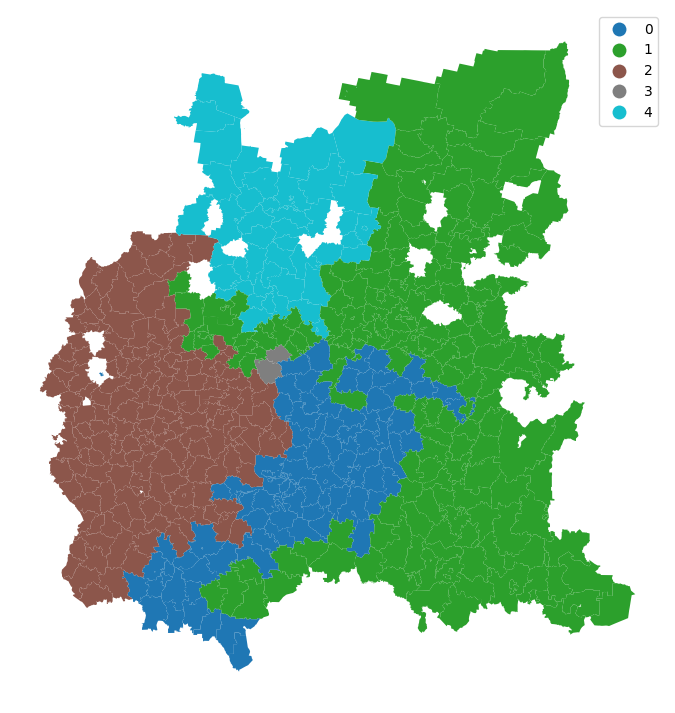
2.1.3 Пространственное распределение кластеров¶
Визуализируем полученные кластеры на карте
muni_clean["ward5wq"] = model.labels_
# Set up figure and ax
f, ax = plt.subplots(1, figsize=(9, 9))
# Plot unique values choropleth including a legend and with no boundary lines
muni_clean.plot(
column="ward5wq",
categorical=True,
legend=True,
linewidth=0,
ax=ax,
)
# Remove axis
ax.set_axis_off()
# Display the map
plt.show()
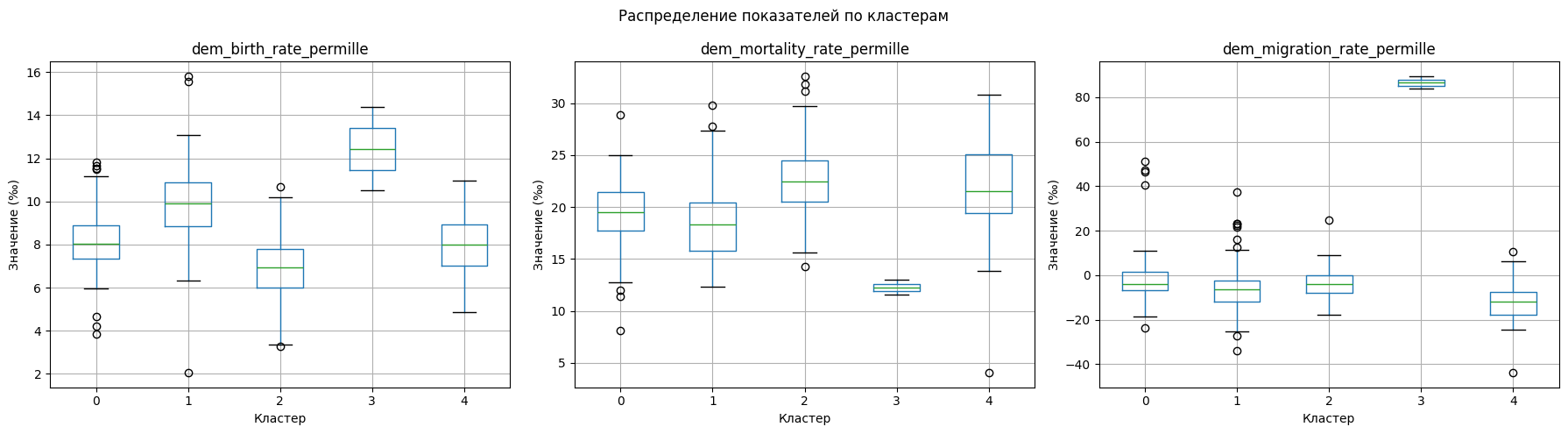
2.1.4 Статистический анализ кластеров¶
Как и в предыдущих разделах рассмотрим профили кластеров.
Количество объектов по кластерам
# Группируем данные по номеру кластера и считаем количество наблюдений в каждом
ward5wqsizes = muni_clean.groupby("ward5wq").size()
ward5wqsizesward5wq
0 96
1 184
2 168
3 2
4 50
dtype: int64Профиль кластеров
Построим boxplot-диаграммы по каждому показателю в разрезе кластеров. Такой способ визуализации позволяет оценить не только средний уровень признака, но и его вариацию, медиану и возможные выбросы внутри каждой группы.
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
for i, col in enumerate(cols_analysis):
muni_clean.boxplot(
column=col,
by="ward5wq",
ax=axes[i]
)
axes[i].set_title(f"{col}")
axes[i].set_xlabel("Кластер")
axes[i].set_ylabel("Значение (‰)")
plt.suptitle("Распределение показателей по кластерам")
plt.tight_layout()
plt.show()
3. Пространственная кластеризация точечных данных¶
В предыдущем разделе мы рассматривали кластеризацию данных на основе их показателей. Теперь перейдём к точечным данным — например, координатам дорожно-транспортных происшествий (ДТП). И посмотрим на то, как мы можем кластризовать данные в пространстве.
0. Подготовка данных¶
Загружаем точечные данные о ДТП в Краснодаре с участием пешеходов (в 2017 году)
dtp_points = gpd.read_file('./data/krs_dtp_ped2017.geojson')
dtp_points = dtp_points.to_crs(dtp_points.estimate_utm_crs())
dtp_points.explore(tiles='cartodbpositron')Skipping field Time: unsupported OGR type: 10
3.1 K-Means на основе координат¶
Возьмём тот же алгоритм k-means, который рассматривался выше, и применим его не к значениям социально-экономических показателей, а непосредственно к координатам точек. В этом случае кластеризация будет выполняться в географическом пространстве и позволит выявить пространственные группы наблюдений.
# Получаем координаты
dtp_points["x"] = dtp_points.geometry.x
dtp_points["y"] = dtp_points.geometry.y
coords = dtp_points[["x", "y"]].values
# Задаем число кластеров
k = 5
model_kmeans = KMeans(n_clusters=k, random_state=42)
model_kmeans.fit(coords)
dtp_points["kmeans_cluster"] = model_kmeans.labels_
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
Смотрим, что получилось
import contextily as ctx
# Перепроецируем в Web Mercator для подложки
dtp_points_web = dtp_points.to_crs(epsg=3857)
fig, ax = plt.subplots(figsize=(8, 8))
dtp_points_web.plot(
column="kmeans_cluster",
categorical=True,
markersize=5,
legend=True,
ax=ax
)
# Добавляем подложку
ctx.add_basemap(
ax,
source=ctx.providers.CartoDB.Positron
)
ax.set_axis_off()
plt.title("K-Means кластеризация ДТП")
plt.show()
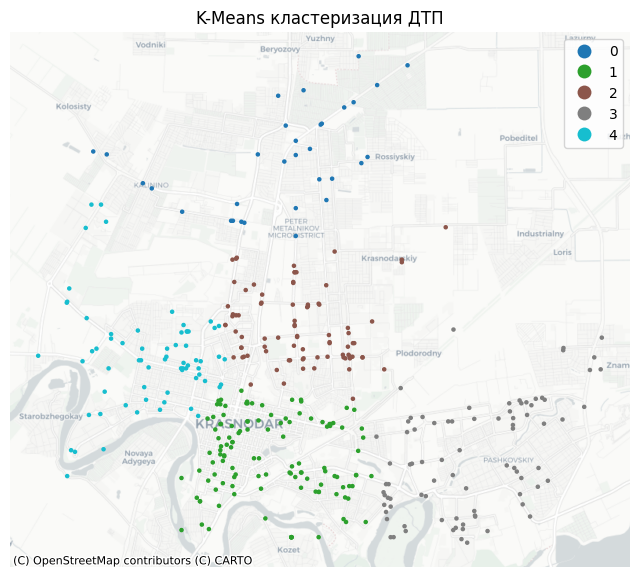
Ограничения K-Means для точечных данных
требуется заранее задать число кластеров k;
метод ориентирован на компактные (условно «круглые») группы и хуже описывает вытянутые структуры, например вдоль дорог;
алгоритм чувствителен к выбросам и неоднородной плотности точек;
все наблюдения принудительно относятся к одному из кластеров, то есть «шум» и редкие события не выделяются отдельно.
Поэтому для поиска «горячих точек» ДТП K-Means может быть менее удобен, чем плотностные методы (например, DBSCAN).
3.2 DBSCAN - плотностная кластризация¶
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) — это алгоритм, который формирует кластеры на основе локальной плотности точек.
В отличие от K-Means, он:
не требует заранее задавать число кластеров;
выявляет кластеры произвольной формы;
позволяет выделять шум (единичные наблюдения).
Алгоритм задаётся двумя параметрами:
eps— радиус окрестности;min_samples— минимальное число точек внутри этого радиуса для формирования плотной области.
Точка считается ядром (core point), если в её окрестности достаточно соседей. Из таких ядер формируются кластеры — к ним добавляются все плотностно достижимые точки. Если точка не относится ни к одному плотному участку, она помечается как шум.
Таким образом, DBSCAN выделяет не геометрические сегменты, а области повышенной концентрации событий, что особенно полезно при анализе ДТП и других точечных данных.
from sklearn.cluster import KMeans, DBSCAN
# Важно: масштабирование не требуется,
# так как координаты уже в метрах
model_dbscan = DBSCAN(
eps=300, # радиус 300 метров
min_samples=5 # минимум 10 точек
)
model_dbscan.fit(coords)
gdf["dbscan_cluster"] = model_dbscan.labels_
Смотрим, что получилось
fig, ax = plt.subplots(figsize=(8, 8))
gdf.plot(
column="dbscan_cluster",
categorical=True,
markersize=5,
legend=True,
ax=ax
)
plt.title("DBSCAN кластеризация ДТП")
plt.show()
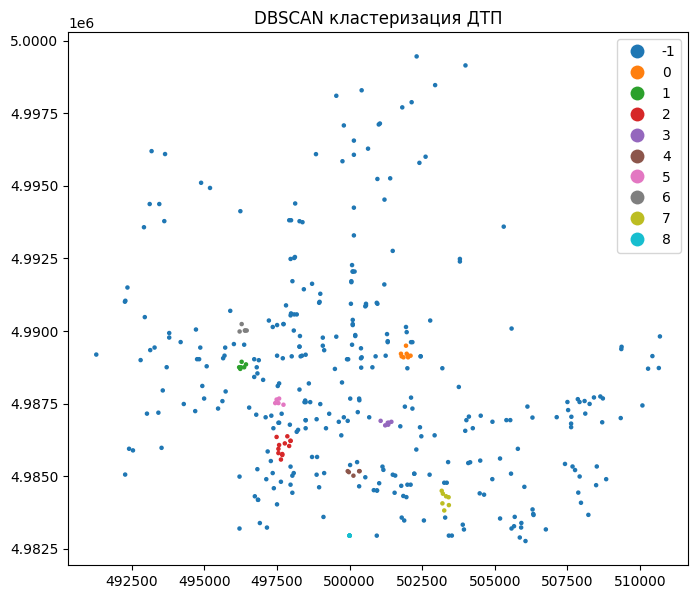
3.3 Сравнение k-means и DBSCAN¶
K-Means:
делит пространство на k групп на основе близости к центрам кластеров;
подходит для пространственной сегментации территории;
формирует компактные группы, но не ориентирован на выявление локальных концентраций;
не выделяет шум — каждое наблюдение относится к одному из кластеров.
DBSCAN:
выявляет зоны повышенной плотности ДТП;
позволяет обнаруживать проблемные участки дорожной сети;
выделяет редкие и одиночные события как шум;
формирует кластеры произвольной формы (например, вытянутые вдоль магистралей).
4.Итог¶
В данном разделе были рассмотрены методы кластеризации и регионализации
Мы показали, что:
кластеризация позволяет выявлять группы территорий по сходству признаков;
результат зависит от выбранного алгоритма;
добавление пространственного ограничения изменяет структуру групп;
Также были рассмотрены методы пространственной кластеризации точечных данных — в частности, алгоритмы K-Means и DBSCAN, позволяющие выявлять пространственные группы и зоны концентрации событий.
Выбор метода должен определяться на основе изначальной исследовательской задачи